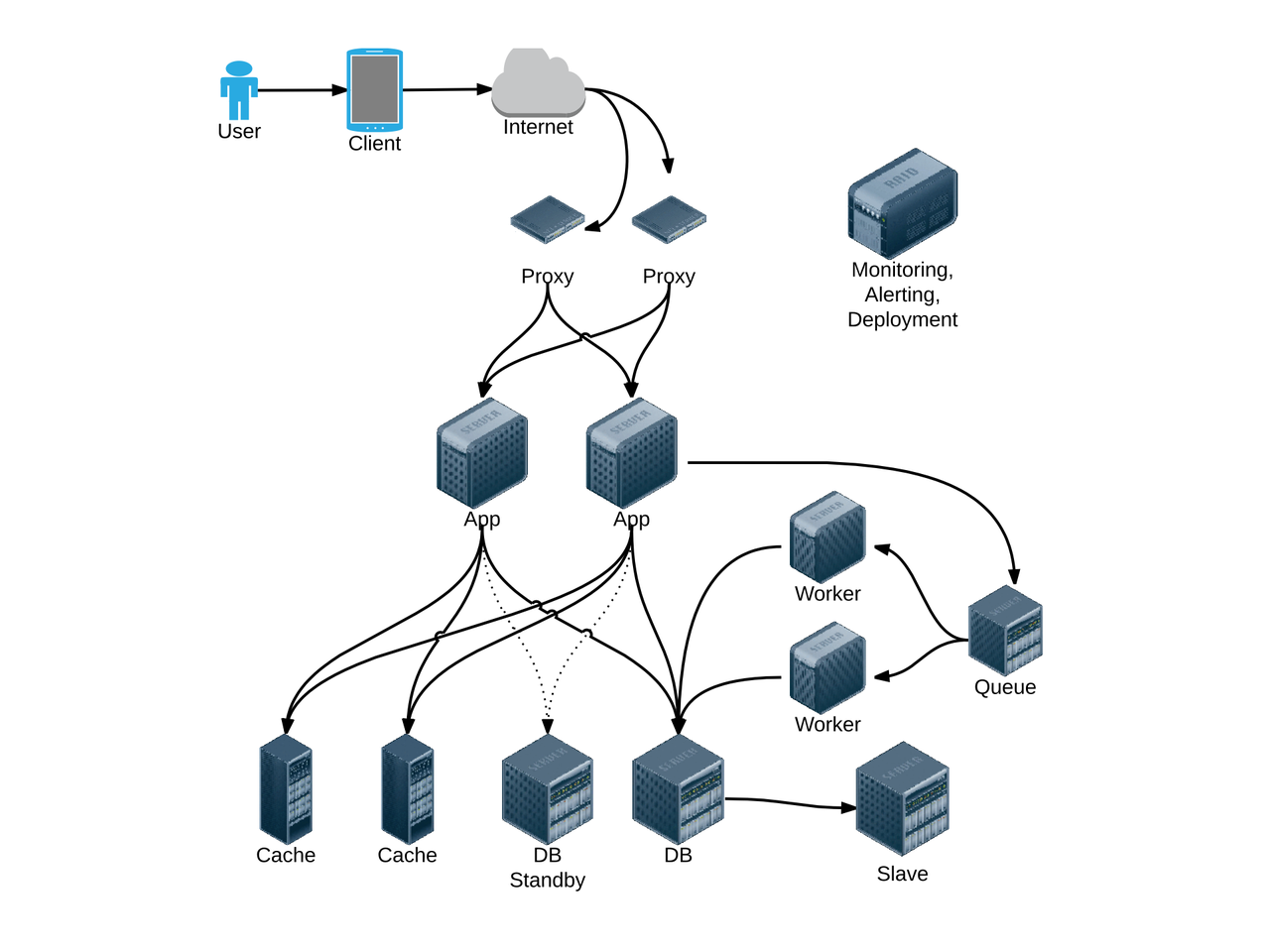
aptly 0.7 has been released today. aptly is a Debian
repository management tool, it allows to mirror remote repositories, create local
package repositories, manage repositories snapshots and publish them back
as Debian repository. aptly main idea is "owning your own repository": you
can mix and match official repos, 3rd-party repositories, your own packages,
creating your own stable/testing/whatever repositories, allowing reproducible
package installations along with controlled upgrades. It is available for download as
binary executables or from Debian repository:
deb http://repo.aptly.info/ squeeze main
When installing from repository, don't forget to import key used to sign the release:
$ gpg --keyserver keys.gnupg.net --recv-keys 2A194991
$ gpg -a --export 2A194991 | sudo apt-key add -
Aptly has new logo, soon I'm going to launch new website:

Most important new features are:
Publishing to Amazon S3
aptly can publish repositories directly to Amazon S3.
First, create new S3 bucket using AWS console. Let it be aptly-repo. Remember Amazon region
you have used to create, I'll be using us-west-1 in this example. If you're going to
have public repository, enable website hosting for that bucket.
Go to IAM page, create new user, save access key ID and secret access key and create bash script
aws.creds.sh:
# Access Key ID:
# AKIAISHG7G3H8AWBCFG
# Secret Access Key:
# E7aujXChaMZwp3ghfk45+Zabd55
export AWS_ACCESS_KEY_ID="AKIAISHG7G3H8AWBCFG" AWS_SECRET_ACCESS_KEY="E7aujXChaMZwp3ghfk45+Zabd55"
In IAM console, attach new custom policy for that user:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1405592139000",
"Effect": "Allow",
"Action": [
"s3:DeleteObject",
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::aptly-repo/*", "arn:aws:s3:::aptly-repo"
]
}
]
}
This user would have limited access only to the bucket you've created.
Now, configure aptly, edit configuration file ~/.aptly.conf and add key S3PublishEndpoints:
"S3PublishEndpoints": {
"aptly-repo": {
"region": "us-west-1",
"bucket": "aptly-repo",
"acl": "public-read"
}
}
If you're going to have public repository, set acl to public-read, otherwise set
acl to private. Now you're ready to do your first publish. For example, to publish
snapshot my-snapshot to the mentioned bucket, run:
aptly publish snapshot my-snapshot s3:aptly-repo:
As with publishes to local filesystem, you can publish under prefix:
aptly publish snapshot my-snapshot s3:aptly-repo:debian/
All regular publish commands are supported: you can switch between snapshots (atomically),
update published local repositories, drop published repos, etc. aptly would do its best to upload
package files only once to package pool in S3.
In order to use published repository, for public repositories use regular HTTP protocol in
/etc/apt/sources.list:
deb http://s3-us-west-1.amazonaws.com/aptly-repo wheezy main
For private repositories you would need special apt s3 transport,
after installing transport you can use it like that:
deb s3://AWS_ACCESS_ID:[AWS_SECRET_KEY_IN_BRACKETS]@s3-us-west-1.amazonaws.com/aptly-repo wheezy main
Package Queries
Before 0.7, aptly supported only Debian dependency-like package queries. In version 0.7, complex queries
were introduced. Query syntax matches reprepro query language, reference could be found in the
docs. I'll give some examples.
Now you can filter mirrors to include only packages with limited priorities:
aptly mirror create -filter="Priority (required)" wheezy-required http://mirror.yandex.ru/debian/ wheezy main
Or download single packages and all its dependencies:
aptly mirror create -filter="nginx" -filter-with-deps wheezy-required http://mirror.yandex.ru/debian/ wheezy main
Pull packages with complex conditions:
aptly snapshot pull snapshot1 source snapshot2 '!Name (% *-dev), $Version (>= 3.5)'
Or remove packages based on query:
aptly repo remove local-repo 'Name (% http-*) | $Source (webserver)'
In the next version, package queries would be used to filter snapshots, search for packages in
repos/snapshots and local repos, and do whole "world" package searching.
Other Features
aptly can now pull all matching packages with aptly snapshot pull command using flag -all-matches, e.g.
one can pull subset of versions from 0.7 to 0.9:
aptly snapshot pull stable1 foo-snapsot stable2 'foo (>= 0.7), foo (<= 0.9)'
Download speed could be limited while mirroring using config option downloadSpeedLimit, so that aptly
won't consume all bandwidth.
All Changes
Full ist of changes since 0.7: